Research
Current projects
- Concatenative AbS
- recognizing speech in noise by synthesizing it non-parametrically
- Parametric AbS
- recognizing speech in noise by synthesizing it parametrically
- MESSL
- Model-based EM Source Separation & Localization
- Auditory bubbles
- mapping the importance of "glimpses" of speech
Past projects
- GestureDB
- a database for gesture-driven workloads
- Autotagging
- automatically describing music from its sound
- Dissertation
- Binaural Model-Based Source Separation & Localization
- Intonation
- how do singers tune in various contexts?
- Major Miner
- music labeling game
- RLRS
- the recti-linear room simulator
- Music similarity
- and playlist generation
- IGMM
- implementation of the Infinite Gaussian Mixture Model
Concatenative analysis-by-synthesis
recognizing speech in noise by synthesizing it non-parametrically

Current approaches to source separation and speech enhancement typically attempt to modify the noisy signal in order to make it more like the original, leading to distortions in target speech and residual noise. In contrast, this project uses the innovative approach of driving a speech synthesizer using information extracted from the noisy signal to create a brand new, high quality, noise-free version of the original sentence. This project aims to produce a high quality speech resynthesis system by modifying a concatenative speech synthesizer to use a unit-selection function based on a novel deep neural network (DNN) architecture.
- The IEEE GlobalSIP 2014 paper introducing the project for noise suppression (Demo)
- The WASPAA 2015 paper using it for bandwidth enhancement and recovery from coding artifacts (Demo)
- This work is supported by a grant from the National Science Foundation and by a 2013 Google Faculty Research Award
Parametric analysis-by-synthesis
recognizing speech in noise by synthesizing it parametrically

Reconstructing damaged, obscured, or missing speech can improve its intelligibility to humans and machines and its audio quality. This project introduces the use of an unmodified large vocabulary continuous speech recognizer as a parametric prior model for speech reconstruction. By driving the recognizer to synthesize realistic speech that is similar to the reliable regions of the noisy observation, it can improve recognition and reconstruction accuracy.
- The ICASSP 2014 paper introducing the project
- The poster I presented there
- This work is supported by a grant from the National Science Foundation
MESSL
Model-based EM Source Separation & Localization

MESSL performs multichannel spatial clustering to separate and localize sources in underdetermined, reverberant mixtures. Its output is an estimate of the regions of the spectrogram that each source dominates and estimates of the interaural parameters (interaural time, phase, and level differences) for each source at each pair of microphones. It makes no assumptions about the sources themselves or the geometry of the microphones or room.
- Code for binaural and multichannel MESSL on GitHub
- The paper in IEEE Transactions of Audio, Speech, and Language Processing 2010 describing the original MESSL.
- EUSIPCO 2015 paper using MESSL in a Markov random field to smooth its mask estimates
- ASRU 2015 paper introducing multichannel MESSL
- Interspeech 2016 paper on using multichannel MESSL to drive minimum variance distortionless response beamforming
- This work is supported by a 2015 Google Faculty Research Award
Auditory bubbles
mapping the importance of "glimpses" of speech

Predicting the intelligibility of noisy recordings is difficult and most current algorithms treat all speech energy as equally important to intelligibility. We have developed a listening test paradigm and associated analysis techniques that show that energy in certain time-frequency regions is more important to intelligibility than others and can predict the intelligibility of a specific recording of a word in the presence of a specific noise instance. The analysis learns a map of the importance of each point in the recording's spectrogram to the overall intelligibility of the word when glimpsed through ``bubbles'' in many noise instances. The important regions identified by the model from listening test data agreed with the acoustic phonetics literature.
- WASPAA 2013 paper introducing the project (presented poster)
- INTERSPEECH 2014 paper exploring generalization to new mixtures (presented poster)
- CogMIR talk on applying this technique to musical timbre understanding
- Interspeech 2016 paper on using this technique to compare human and ASR listeners directly on recognizing GRID sentences
- This work is supported by a 2015 PSC-CUNY grant
Past projects
GestureDB
a database for gesture-driven workloads

I'm collaborating with Prof. Arnab Nandi on a gestural interface for querying databases. Instead of typing SQL commands, the user manipulates representations of database objects, while the database provides immediate feedback. This feedback allows the user to quickly explore the schema and data in the database with fluid, multi-touch gestures. I designed the gesture classification system, which is able to take advantage of the proximity of interface elements and compatibility of schema and data objects.
- The GestureDB website, including a demonstration video
- The VLDB 2014 paper describing the system [coming soon!]
- The CHI 2013 Work-in-progress paper describing an iPad implementation
- The poster associated with the CHI 2013 WIP paper
Autotagging
automatically describing music from its sound

With tens of millions of songs on iTunes and spotify, people need better ways to explore large music collections. We propose using various machine learning algorithms to classify 10-second clips of songs according to a number of human-generated "tags", short textual descriptions like "male vocals", "acoustic", "guitar", and "folk". We have performed many experiments in collecting such data, the properties of the data, modeling the data by itself as a language model, and modeling the data with various features extracted from the audio.
We have found that people use more of the same tags when describing clips from "closer" together in time, meaning that clips from the same track share more tags than clips from the same album, which share more tracks that clips from the same artist, which share more tags than clips with nothing in common. We have found that tag language models improve classification accuracy on the raw data. And we have found that while support vector machines work well for classification, restricted Boltzmann machines and multi-layer perceptrons work better.
- Demonstration website of our autotagging system on a collection of popular music.
- The JMLR paper describing the classification restricted Boltzmann machine and results on autotagging data.
- The ToMCCAP 2010 paper describing the use of various tag language models to improve tag classification performance.
- The arXiv manuscript describing our experiments with conditioned restricted Boltzmann machines as tag language models to improve autotagging performance.
- The ISMIR 2010 paper describing our experiments using Amazon Mechanical Turk for data collection and measuring tag co-occurrence as a function of temporal "distance".
- The JNMR 2008 paper introducing our human computation game for data collect and our classification approach.
Dissertation
Binaural Model-Based Source Separation & Localization
When listening in noisy and reverberant environments, human listeners are able to focus on a particular sound of interest while ignoring interfering sounds. Computer listeners, however, can only perform highly constrained versions of this task. While automatic speech recognition systems and hearing aids work well in quiet conditions, source separation is necessary for them to be able to function in these challenging situations.
This dissertation introduces a system that separates more than two sound sources from reverberant, binaural mixtures based on the sources' locations. Each source is modelled probabilistically using information about its interaural time and level differences at every frequency, with parameters learned using an expectation maximization (EM) algorithm. The system is therefore called Model-based EM Source Separation and Localization (MESSL). This EM algorithm alternates between refining its estimates of the model parameters (location) for each source and refining its estimates of the regions of the spectrogram dominated by each source. In addition to successfully separating sources, the algorithm estimates model parameters from a mixture that have direct psychoacoustic relevance and can usually only be measured for isolated sources. One of the key features enabling this separation is a novel probabilistic localization model that can be evaluated at individual time-frequency points and over arbitrarily-shaped regions of the spectrogram.
The localization performance of the systems introduced here is comparable to that of humans in both anechoic and reverberant conditions, with a 40% lower mean absolute error than four comparable algorithms. When target and masker sources are mixed at similar levels, MESSL's separations have signal-to-distortion ratios 2.0 dB higher than four comparable separation algorithms and estimated speech quality 0.19 mean opinion score units higher. When target and masker sources are mixed anechoically at very different levels, MESSL's performance is comparable to humans', but in similar reverberant mixtures it only achieves 20–25% of human performance. While MESSL successfully rejects enough of the direct-path portion of the masking source in reverberant mixtures to improve energy-based signal-to-noise ratio results, it has difficulty rejecting enough reverberation to improve automatic speech recognition results significantly. This problem is shared by other comparable separation systems.
- Download it as a single pdf (7.6 MB)
- Download separate chapters as pdfs (some of the internal links don't work):
- Front matter (142 KB)
- Chapter 1: Introduction (450 KB)
- Chapter 2: Literature review (979 KB)
- Chapter 3: Statistics of interaural parameters (2.5 MB)
- Chapter 4: Localization (1.8 MB)
- Chapter 5: Separation (1.9 MB)
- Chapter 6: Evaluation (335 KB)
- Chapter 7: Conclusion (74 KB)
- Bibliography (210 KB)
- Get the matlab code on github
Intonation
how do singers tune in various contexts?

I've collaborated with Prof. Johanna Devaney on her work studying the effect of context on singers' intonation. We're looking at how singers change their tuning based on the harmonic context of other singers, based on the presence of accompaniment, and based on the melodic context of individual lines. We do this by analyzing recordings of the singers using automated and semi-automated tools we have developed. These tools have been released as the Automatic Music Performance and Analysis Toolkit (AMPACT) on github.
- The AMPACT code on Github.
- The ISMIR 2012 paper describing the AMPACT toolkit and its use to analyze a set of choral recordings.
- The Psychomusicology journal paper providing an overview of this work and some example analyses.
- The WASPAA 2011 paper describing our characterization of note slope and curvature using discrete cosine transform coefficients.
- The WASPAA 2009 paper describing our technique for improving MIDI-audio alignments.

Major Miner
music labeling game
I built a human computation game called Major Miner's music labeling game. From the intro:
The goal of the game, besides just listening to music, is to label songs with original, yet relevant words and phrases that other players agree with. We're going to use your descriptions to teach our computers to recommend music that sounds like the music you already like.
Players are having a good time with it. You can see the top scorers on the leader board, but don't let them intimidate you, it's pretty easy to score points once you get the hang of it. Check it out if you have some time to play.
RLRS
the recti-linear room simulator

This code will generate binaural impulse responses from a simulation of the acoustics of a rectilinear room using the image method. It has a number of features that improve the realism and speed of the simulation. It can generate a pair of 680 ms impulse responses sampled at 22050 Hz in 75 seconds on a 1.8 GHz Intel Xeon. It's easy to run from within scripts to generate a large set of impulse responses programmatically.
To improve the realism, it applies anechoic head-related transfer functions to each incoming reflection, allows fractional delays, includes frequency-dependent absorption due to walls, includes frequency- and humidity-dependent absorption due to air, and varies the speed of sound with temperature. It also randomly perturbs sources in proportion to their distance to the listener to simulate imperfections in the alignment of the walls.To improve simulation speed, it performs all calculations in the frequency domain and the complex exponential generation code is written in C, it only calculates the Fourier transforms of anechoic HRTFs as it needs them, and then it caches them, and it culls sources that are beyond the desired impulse response length or are significantly quieter than the direct path.
Related stuff:
- The github repository
- The blog post I wrote introducing it
Music similarity
and playlist generation
Graham Poliner, Dan Ellis, and I built a system to automatically generate playlists based on acoustic similarity of songs. This work went into our two publications, the first in the ACM Multimedia Systems Journal and the second as ISMIR 2005. The systems use SVM active learning to try to determine what you want to listen to. Take a look at the demo I put together for it.
In addition to the papers, a system based on this idea came in first place in the MIREX 2005 Artist identification competition at ISMIR and second place in the Genre identification competition.
Related stuff:
- LabROSA demo page
- The paper we published in the ACM Multimedia Systems Journal, May 2006.
- The paper we published at ISMIR 2005.
- The extended abstract about the system that won MIREX 2005 Artist ID.
- The results of MIREX 2005, including the extended abstracts for all of the competing systems.
IGMM
implementation of the Infinite Gaussian Mixture Model
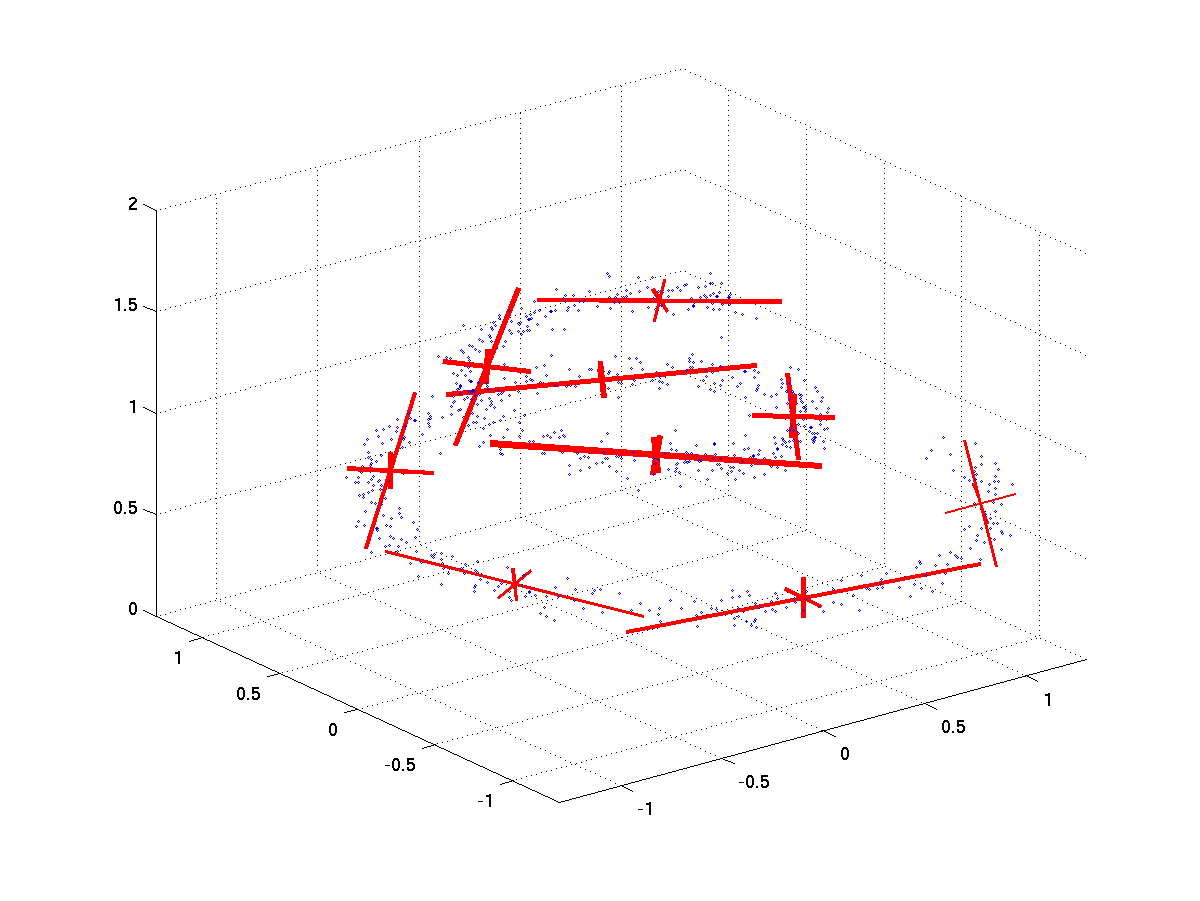
For my final project in Tony Jebara's Machine Learning course, cs4771, I implemented Carl Rasmussen's Infinite Gaussian Mixture Model. I got it working for both univariate and multivariate data. I'd like to see what it does when presented with MFCC frames from music and audio. There were some tricky parts of implementing it, I wrote them up in a short paper describing my implementation. Since I've gotten the multivariate case working, I'll trust you to ignore all statements to the contrary in the paper. The IGMM requires Adaptive Rejection Sampling to sample the posteriors of some of its parameters, so I implemented that as well. Thanks to Siddharth Gopal for a bugfix.
Download related pieces:
- The paper I wrote about implementing it.
- The github repository
- Jacob Eisenstein's Dirichlet process mixture model, which adds some cool features to the infinite GMM.